方案描述:
(1) 提出了一個基于深度學(xué)習的護目鏡佩戴檢測算法:
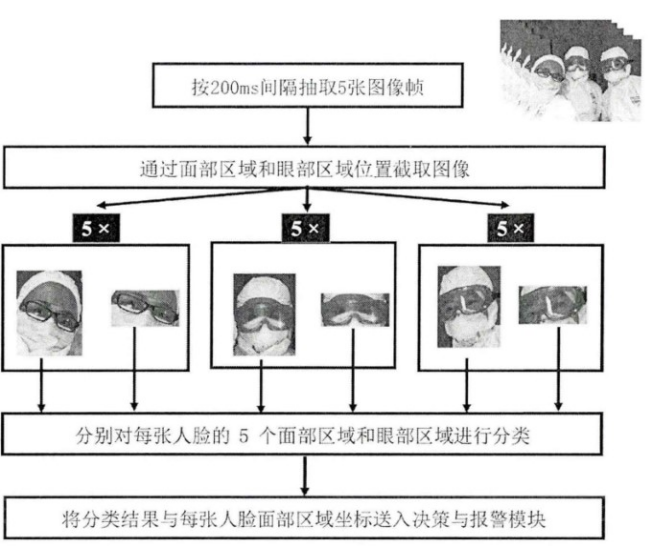
通過對深度殘差網絡模型的研究,結合護目鏡佩戴檢測的具(jù)體(tǐ)使用(yòng)場景,我們在原有(yǒu)深度殘差網絡的基礎上,增加了池化層 MAXPOOL和非線(xiàn)性激勵層RELU,減少網絡參數,提高了網絡的不變性。引入Dropout機制,極大地減緩了過拟合現象的發生,提高了模型預測護目鏡佩戴情況的準确率。同時,結合護目鏡與普通眼鏡在特征上的相似性,引入了包含普通眼鏡分(fēn)類的預訓練模型,對護目鏡佩戴情況的檢測準确率有(yǒu)很(hěn)大幫助。
(2) 建立一個護目鏡佩戴圖像數據集:
由于在護目鏡佩戴情況檢測過程中(zhōng),人臉面部區(qū)域的大小(xiǎo)、眼部區(qū)域的大小(xiǎo)、攝像頭拍攝時的角度和距離、光照和遮擋情況,都會對人臉檢測和護目鏡佩戴情況的分(fēn)類造成影響,選取了各類情況下(室内/室外,不同光照條件,不同角度,不同遮擋情況)的真實場景圖像。同時,由于護目鏡佩戴圖像的數據量較小(xiǎo),開發一種基于人臉特征點的護目鏡佩戴圖像合成算法,分(fēn)别生成左右兩半部分(fēn)的貼合人臉的護目鏡圖片,給各類人臉圖像中(zhōng)的人物(wù)“佩戴”護目鏡,一定程度上豐富了數據集,提高了護目鏡佩戴檢測算法的泛化能(néng)力。标注完成後,共在1607張可(kě)能(néng)包含多(duō)張人臉的圖像中(zhōng)得到了3108張面部區(qū)域及眼部區(qū)域圖像。





 粵公(gōng)網安(ān)備 44030502003347号
粵公(gōng)網安(ān)備 44030502003347号



